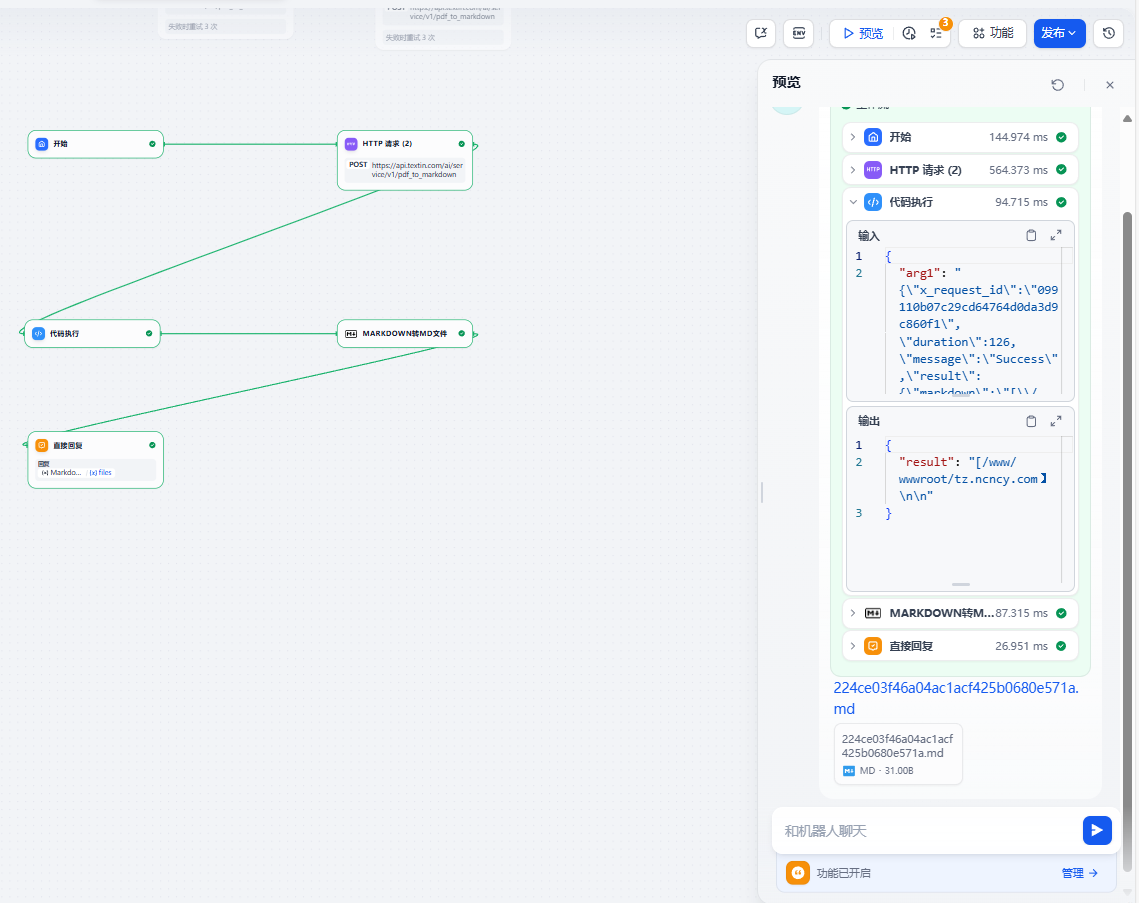
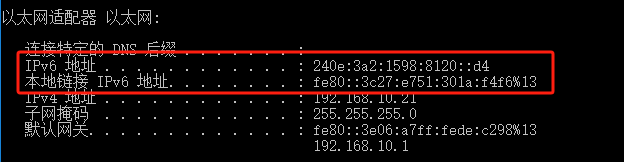
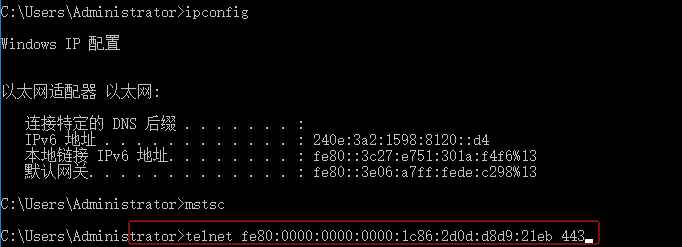
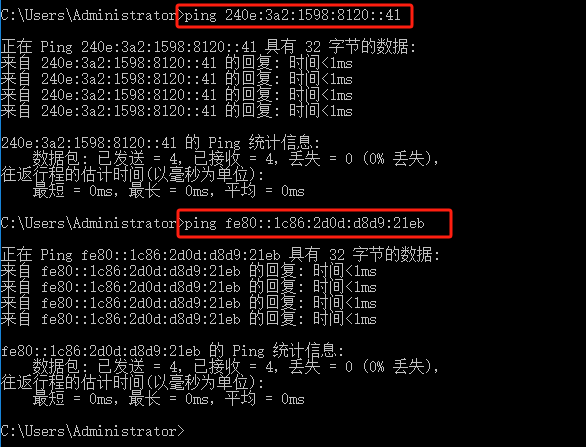
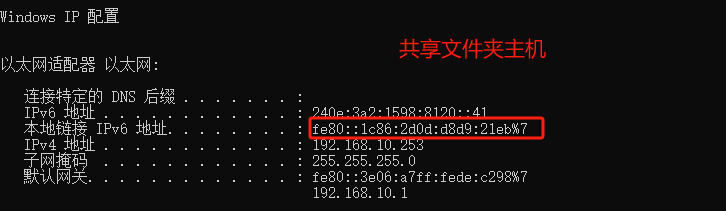
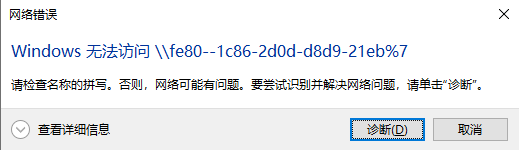
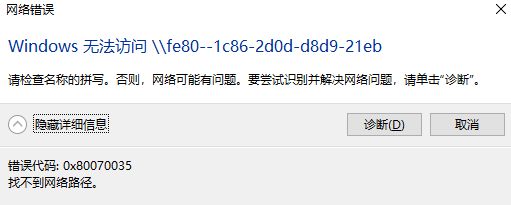
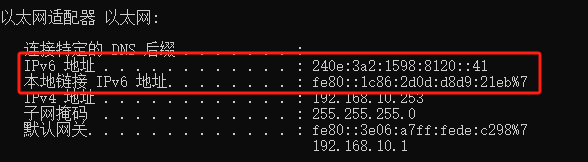
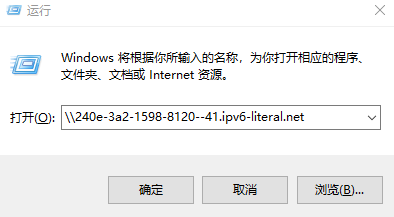
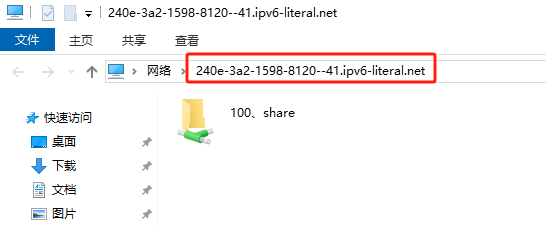
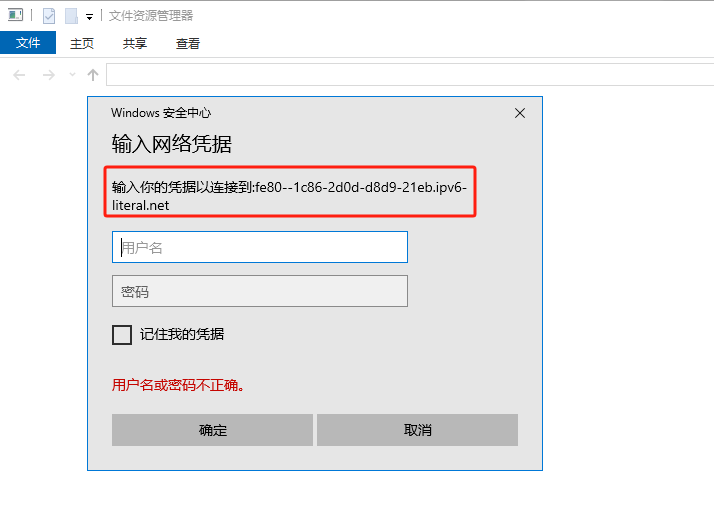
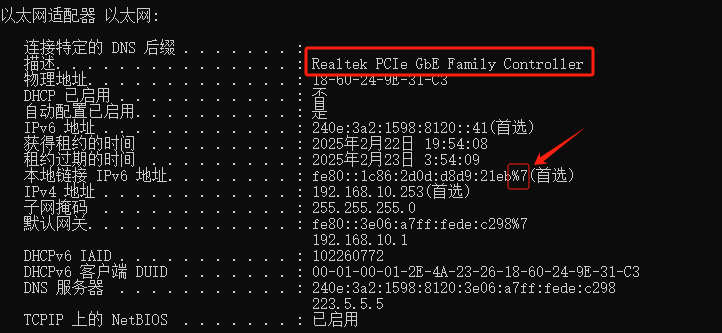
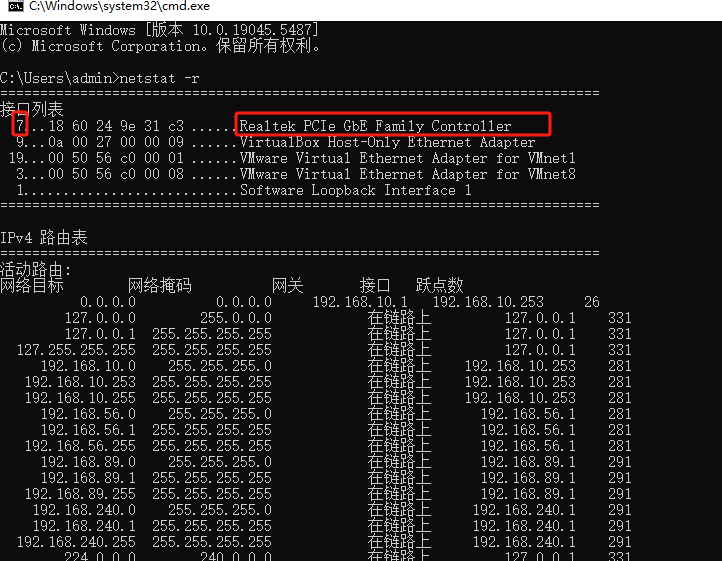
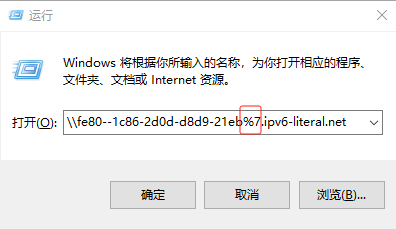
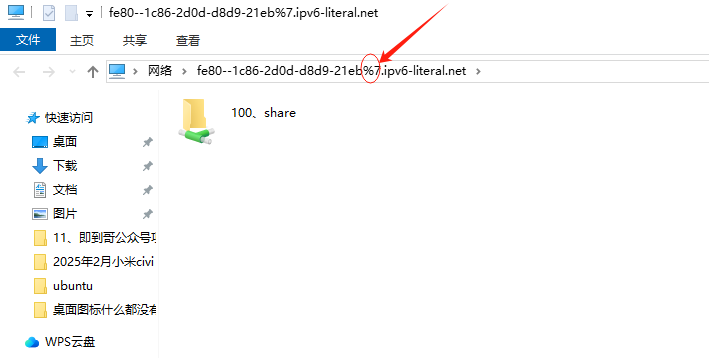
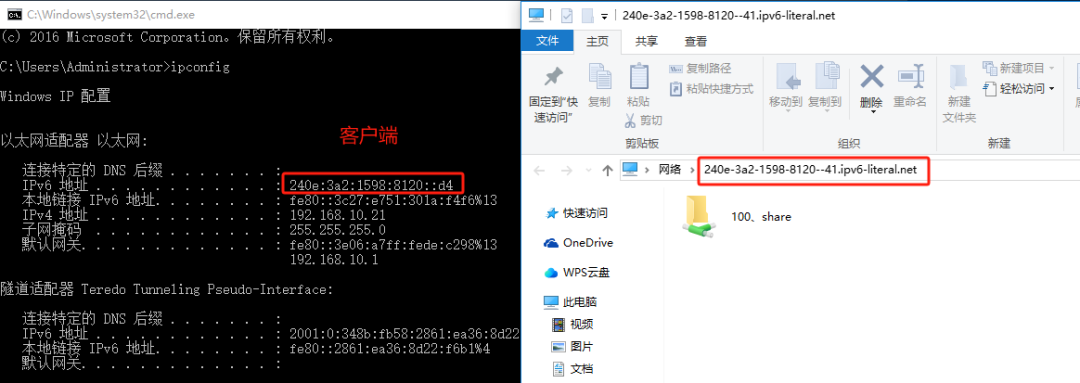
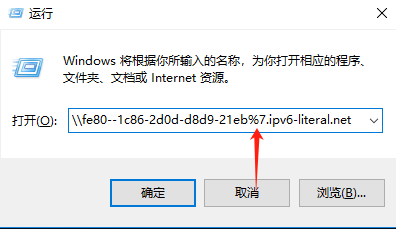
如果你遇到Red Hat如下问题,可以尝试使用docker运行Aria2
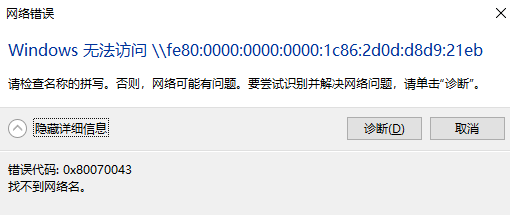
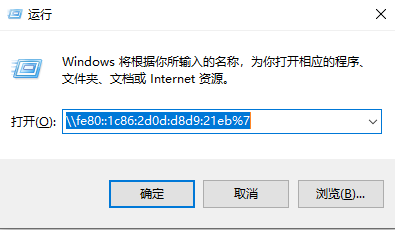
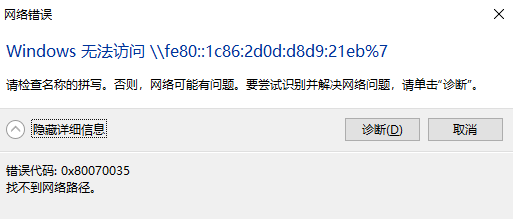
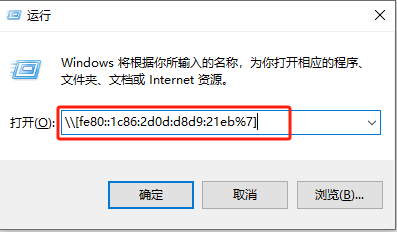
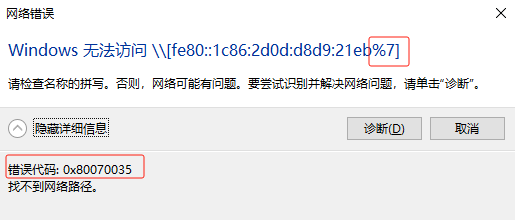
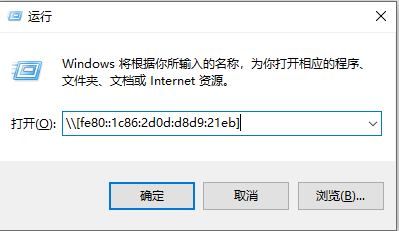
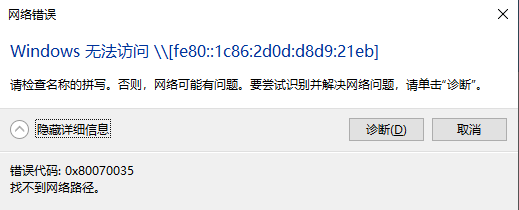
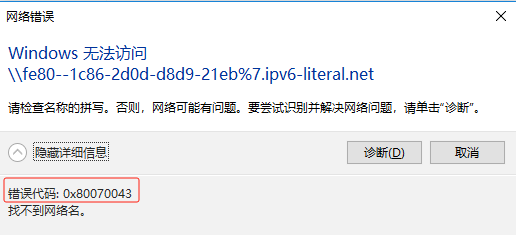
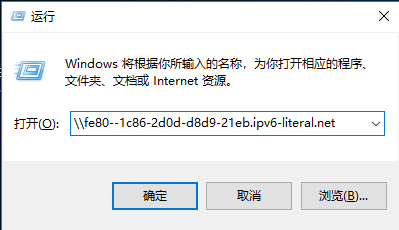
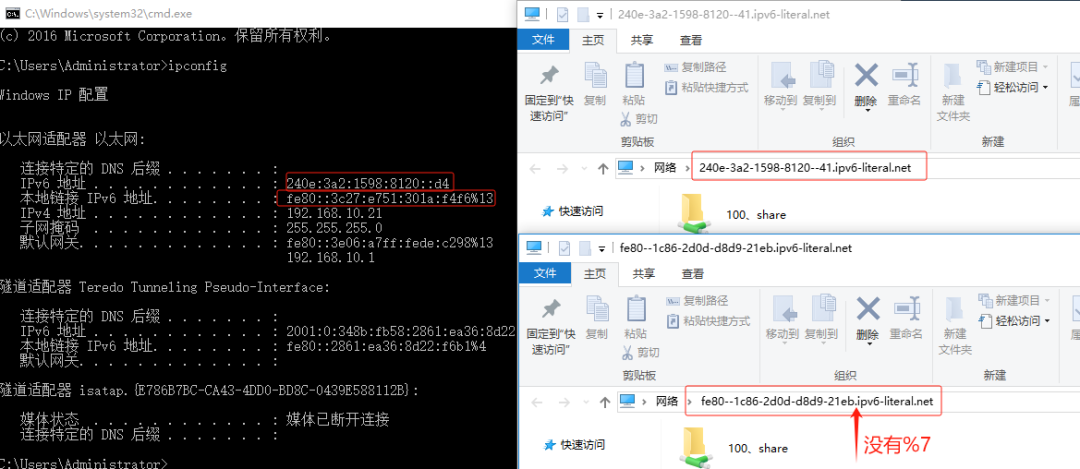
无法读取客户身份 本系统尚未在权利服务器中注册。可使用 “rhc” 或 “subscription-manager” 进行注册。
# subscription-manager register 注册到:subscription.rhsm.redhat.com:443/subscription 用户名: xxxx 密码: xxx 无法注册到任何机构。
使用 Docker Compose 部署
Alist 有官方的 Docker 镜像和部署文档。但我更倾向于使用 Docker Compose 来管理部署,这样可以将它和Aria2 Pro或其他应用一起部署。
前置工作
- 你的服务器、主机上需要安装 Docker 和 Docker Compose。
- 请熟悉 Docker 中的 volume 和 network。
编写 docker-compose.yml
- 创建一个部署工程文件夹,并编写一个
docker-compose.yml文件,并参environment和volumes节点中照注释(#)进行配置。 ${PWD}指代当前目录,默认配置会将程序产生的数据保存在这个文件中,如果你想将数据保存在其他位置,可以修改volumes配置(:号前为主机上的目录,后为容器内的目录)。
内容如下:
version: "3.8"
services:
# Aria2 Pro 的官方部署文档: https://github.com/P3TERX/Aria2-Pro-Docker/blob/master/docker-compose.yml
Aria2-Pro:
container_name: aria2-pro
image: p3terx/aria2-pro
environment:
- PUID=65534
- PGID=65534
- UMASK_SET=022
- RPC_SECRET=123456 # 配置Aria2 的 RPC secret 密钥,它将被用于 Alist 和 AriaNg 连接 Aria2,默认123456
- RPC_PORT=6800
- LISTEN_PORT=6888
- DISK_CACHE=64M
- IPV6_MODE=false
- UPDATE_TRACKERS=true
- CUSTOM_TRACKER_URL=
- TZ=Asia/Shanghai
volumes:
- ${PWD}/aria2/config:/config
- ${PWD}/aria2/downloads:/downloads # 在:号前配置你要在主机上保存下载文件的路径
ports:
- "6800:6800"
- "6888:6888"
- "6888:6888/udp"
restart: unless-stopped
logging:
driver: json-file
options:
max-size: 1m
# Aria2 的 Web UI
AriaNg:
container_name: ariang
image: p3terx/ariang
command: --port 6880 --ipv6
ports:
- "6880:6880"
restart: unless-stopped
logging:
driver: json-file
options:
max-size: 1m
部署并启动
- 在部署工程文件夹中,执行
docker-compose up -d命令,就能完成部署了。 - 程序成功部署完毕 🥳