先按照如下添加Tracker
以下是抄的motrix 中所使用的github上节点
trackerslist/trackers_best.txt at master · ngosang/trackerslist
trackerslist/trackers_best_ip.txt at master · ngosang/trackerslist
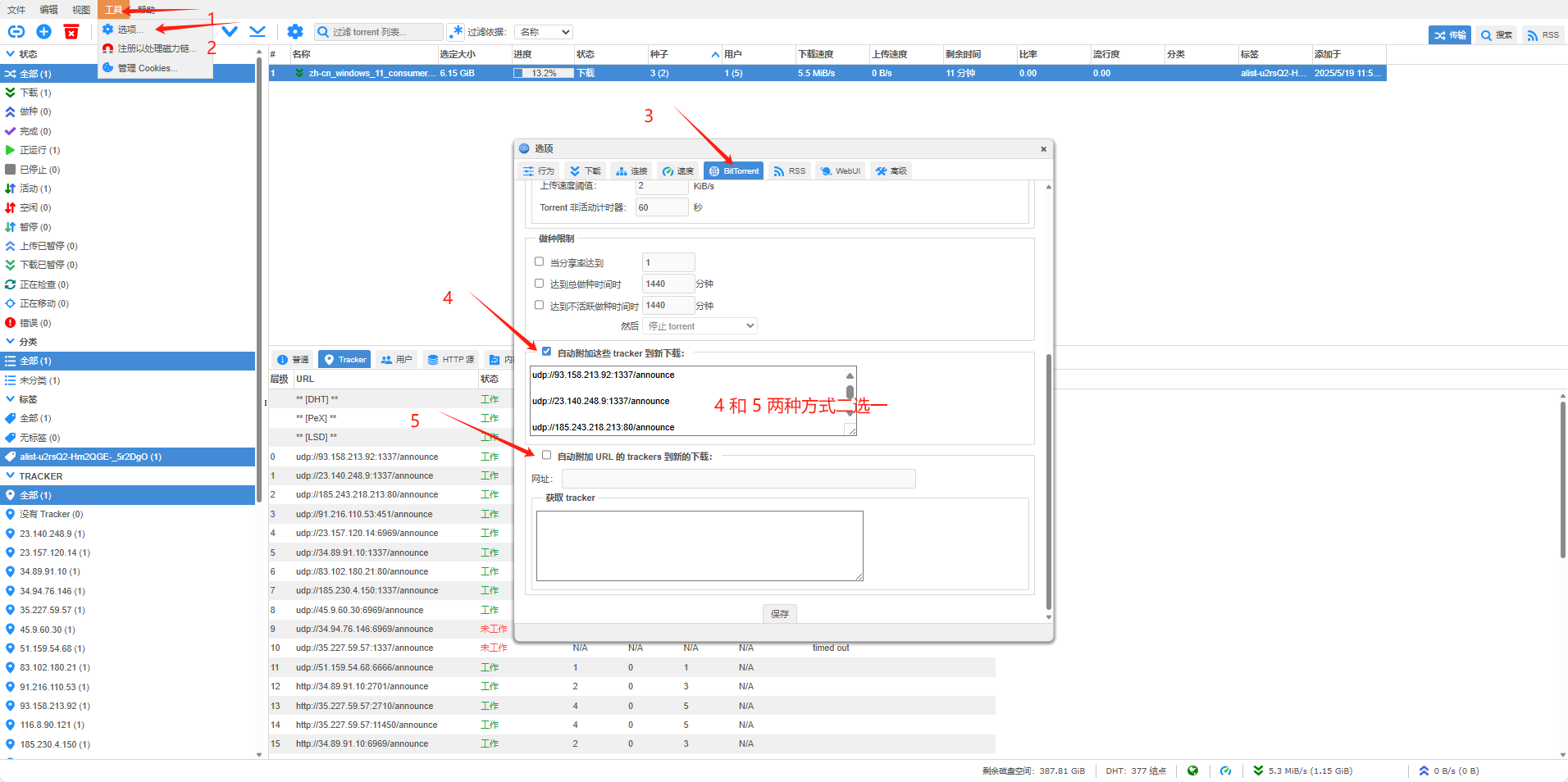
添加完成后下载速度还是很慢的话关闭 备用下载速度限制,关掉就能起飞了
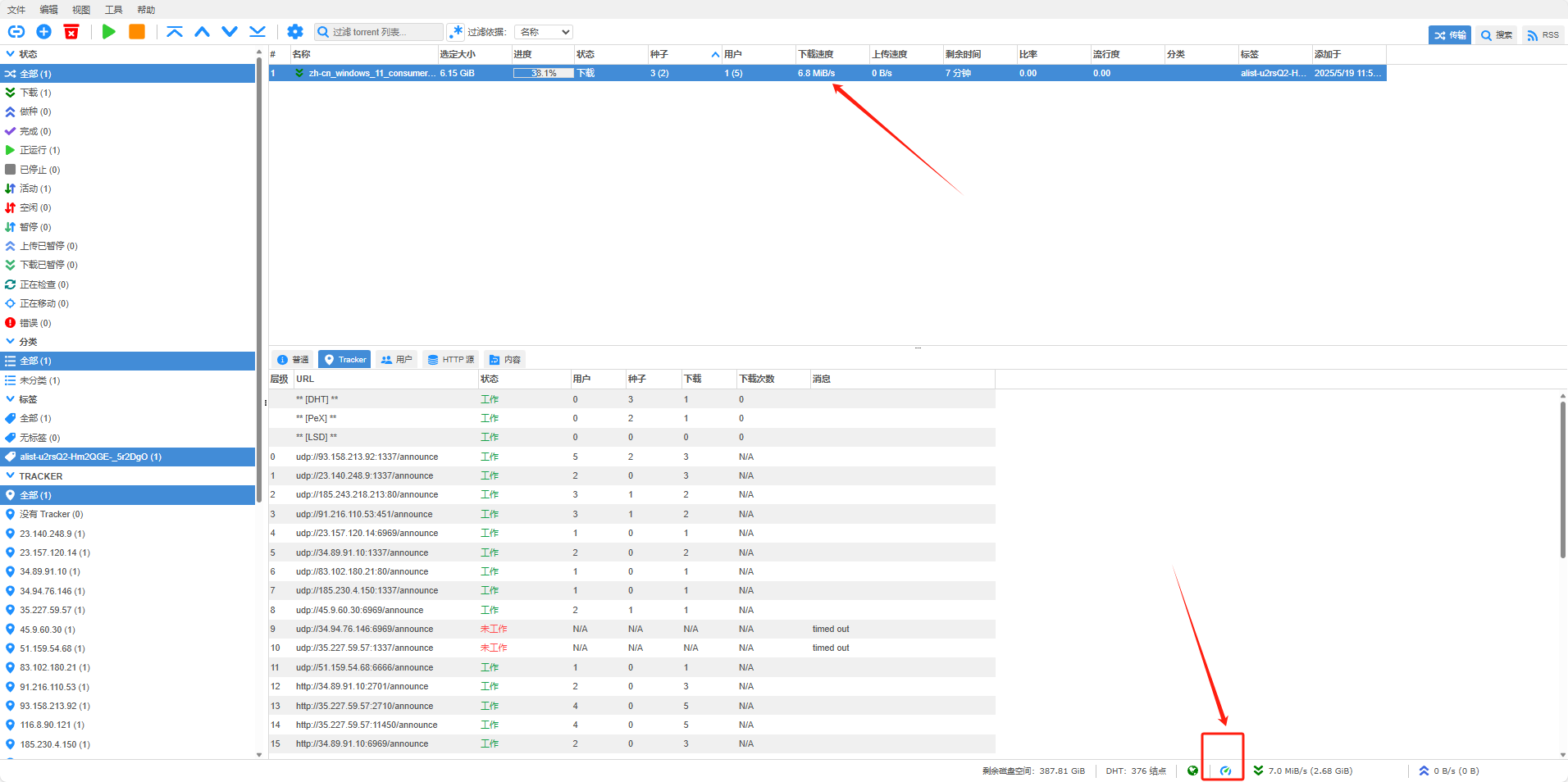
先按照如下添加Tracker
以下是抄的motrix 中所使用的github上节点
trackerslist/trackers_best.txt at master · ngosang/trackerslist
trackerslist/trackers_best_ip.txt at master · ngosang/trackerslist
添加完成后下载速度还是很慢的话关闭 备用下载速度限制,关掉就能起飞了
阅读本文要求具有基础网络知识,例如知道什么是网络掩码、路由、DHCP 等。
当前环境:
- 江苏电信,光猫为桥接模式。
- x86 软路由,安装 iStoreOS。
IPv6 与 v4 不同。v4 时代运营商一般只给用户分配最多 1 个公网 ip,然后用户自己的路由器通过 NAT 再给局域网设备分配内网 IP,也就是 192.168.x.x 这种。这种情况下内网设备没有独立的公网 IP,要想从公网访问必须配置路由器端口转发。随着 v4 资源枯竭,现在运营商默认已经不再分配公网 IP 了。要想正常从外部访问,必须做内网穿透。
IPv6 有无数个地址可供分配,“可以给地球上的每一粒沙子都分配一个 IP 地址”。因此运营商分配的策略也会变化。v4 分配的是一个地址,而 v6 分配的是一个前缀,也就是所谓的 pd,相当于是一整个网段,我们可以自己继续往下分配,从而使得每一个局域网设备都能获得公网 IP 地址,甚至可以划分自己的多层子网。
典型的 IPv6 地址由 8 组十六进制数字表示,一共有 128 bits (16B)。
|----- 网络号 ------| 子网号|--------- 主机号 ---------| 前缀长度|
0123 : 4567 : 89ab : cdef : 0123 : 4567 : 89ab : cdef /64
通常习惯上只有子网号是我们可以自行往下划分的部分,即前缀长度应该在 49~64 范围内。
IPv6 每组的前缀 0 可以省略,多组连续的 0 也可以省略,但要用 :: 表示,例如下面两种写法等价:
204e:0000:0000:0000:0000:0000:0000:1
204e::1与 v4 不同,一个接口可以同时具有多个 v6 的 IP 地址,并且多数情况下都会超过一个。因为 v6 地址分为不同的 Scope,也就是说有效范围不同,常见的(不是全部)包括:
192.168.x.x 之类的局域网地址。多个子网可以通过此类地址互相访问(通过路由器)。其中只有「Link Local」在 IPv4 中没有明确对应,因为它的存在主要为了解决 IPv6 特有的一个问题:一个接口有多个地址,那么建立路由时很可能学习到重复的下一跳,所以需要一个唯一标识来区分设备,这就是 Link Local 地址。
进入 OpenWrt 后台「网络-接口」,编辑 wan 接口(通常都是这个名字),修改这些选项:
wan 口的「DHCP 服务器 – IPv6 设置」:
保存应用后通常会多出一个名为 wan_6 的虚拟动态接口,因为大部分营运商是通过 DHCPv6 下发地址的,而我们之前选择了「自动」,OpenWrt 识别到之后就会新建一个客户端。若运营商支持现在应该就能看到获取的前缀了(PD):

注意,若只有
fe80::开头的地址则说明未获取到 IPv6,这个只是自动生成的链路地址而已。
路由器获得了一个网段,下面要做的就是给每一个设备都分配一个公网地址。有两种方案,可以单独选择也可以同时使用,分别是 SLAAC 与 DHCPv6。
SLAAC 是无状态地址自动配置协议,顾名思义,它不再需要 DHCP 服务器来维护状态,而是各个客户端自行生成、协商、通告地址。SLAAC 是唯一全平台支持的协议,Android 明确不会支持有状态 DHCPv6,谷歌认为有状态协议对于终端用户没有明显优点,还会造成隐私问题,属于 IPv4 时代的陋习。
SLAAC 的一个重要数据是路由器定期发送的 RA(路由通告),其包含前缀信息,以及是否应该尝试通告 DHCPv6 请求地址。
要配置纯 SLAAC,需要进入 「lan 口的设置 – 高级设置」:
::1,那么此接口的地址就类似 240e:aaaa:bbbb:cccc::1。另外还要配置「lan 口的设置 – DHCP 服务器 – IPv6 设置」:
对应地,修改 「IPv6 RA 设置」:
这样保存应用之后,应该所有的下属设备都可以生成公网 IPv6 地址了。
DHCPv6 本身也分为有状态和无状态两种:
要启用 DHCPv6,「lan 口的设置 – 高级设置」与上文 SLAAC 配置一致,「lan 口的设置 – DHCP 服务器 – IPv6 设置」如下:
对应地, 「IPv6 RA 设置」应为:
若希望配置为无状态 DHCPv6,则需要启用 SLAAC,并把 RA 标记设置为 O。即通过 SLAAC 生成 IP 但通过 DHCPv6 获取参数。
现在我们的每一个设备都有公网地址了,但要想被外部访问,需要防火墙放行才行。这里只说 OpenWrt 的防火墙,至于设备自己的(群晖 NAS,Windows 等)自行设置。
进入「网络 – 防火墙 – 通信规则」点击下面的添加按钮:
【常规设置】
【高级设置】
保存一下就好。
注意,这样配置防火墙实际上是允许以 IPv6 访问任意子网设备的指定端口。
如果希望只放行特定的目标设备,可以指定 IP 后缀。因为运营商分配给我们的前缀是动态变化的,所以不能直接指定 IP,而后缀无论是使用 DHCPv6 还是 SLAAC(使用 eui64),经过配置都可以确保不变。然后添加防火墙规则时填写「目标地址」为 ::aaaa:bbbb:cccc:dddd/-64,其中 -64 的意思是匹配从右往左的 64 位。若部分系统不支持这种缩写,可以回退到 IPv4 的掩码表示形式:::aaaa:bbbb:cccc:dddd/::ffff:ffff:ffff:ffff。

240e::/20: 中国电信2409:8000::/20: 中国移动2408:8000::/20: 中国联通2000::/3: 全局单播地址。也就是全球可路由的公网地址。上述三个都属于这个。FE80::/10: 链路本地地址。2002::/16: 仅供 6to4 隧道使用:: – 相当于 0.0.0.0::1/128 – 本地回环地址,相当于 127.0.0.1/32qBittorrent 是一款开源免费的 BitTorrent 客户端,支持多种操作系统,具有简洁易用的界面和丰富的功能,是广大用户进行种子下载的首选工具之一。
以下是 qBittorrent 的一些我认为比较好的主要特点和功能:
开源免费,没有任何商业限制易于使用搜索引擎(插件支持),允许用户直接在客户端中搜索种子文件IPv6支持。物语云可以考虑活动,有流量加倍,黄鸡可能问问老板有没有折扣码了。
1.部署比较简单,这里简单记录一下,新建一个文件start_qbittorrent.sh
确保给脚本执行权限:
chmod +x start_qbittorrent.sh
2.复制代码内容
#!/bin/bash
export QBT_EULA=accept
export QBT_VERSION=latest
export QBT_WEBUI_PORT=8080
export QBT_CONFIG_PATH="/path/to/your/qbit/config"
export QBT_DOWNLOADS_PATH="/path/to/your/downloads"
export QBT_ALIST_TEMP="/opt/alist/data/temp"
docker run \
-t \
--restart=always \
--privileged=true \
--name qbittorrent-nox \
--stop-timeout 1800 \
--tmpfs /tmp \
-e QBT_EULA \
-e QBT_VERSION \
-e QBT_WEBUI_PORT \
-e PGID=0 \
-e PUID=0 \
-p "$QBT_WEBUI_PORT:$QBT_WEBUI_PORT/tcp" \
-p 6881:6881/tcp \
-p 6881:6881/udp \
-v "$QBT_CONFIG_PATH:/config" \
-v "$QBT_DOWNLOADS_PATH:/downloads" \
-v "$QBT_ALIST_TEMP:$QBT_ALIST_TEMP" \
qbittorrentofficial/qbittorrent-nox:"$QBT_VERSION"3.然后运行脚本:
./start_qbittorrent.sh
4.启动 screen 会话,然后在会话中运行脚本:
screen -S qbittorrent5.在新的 screen 会话中,运行你的脚本:
./start_qbittorrent.sh这样关闭终端就不会停止运行了
如果本地环境端口冲突,可以通过环境变量解决, 修改的同时还需要同步修改映射端口
WEBUI_PORT 变量设置为新端口TORRENTING_PORT访问你的 ip:8080 端口

默认用户名是 admin
密码需要查看容器标准输出
docker logs -f qbittorrent
The WebUI administrator password was not set. A temporary password is provided for this session: QFC6j2t3Y
自行添加种子文件或使用磁力链接进行下载

我这里方便,默认我的大内网忽略验证

插件地址 qbittorrent/search-plugins
我这里随便选个最新的插件,复制 Download link

添加插件

添加完成后

验证插件, 随便搜的

Acrobat PRO DC 是一款由Adobe开发的PDF编辑器和阅读器。它的主要功能包括创建、编辑和阅读PDF文件。

1. 创建和编辑PDF文件;
2. 添加、删除、修改PDF文件中的内容;
3. 添加数字签名进行认证;
4. 对PDF文件进行安全性设置;
5. OCR功能,将扫描文档转换为可编辑的PDF文件;
6. 支持多种文件格式的转换。
1. 界面简单直观,易于使用;
2. 稳定性高,操作速度快;
3. 支持多种文件格式的转换和处理;
4. OCR功能强大,可将扫描文档转换为可编辑的PDF文件;
5. 提供丰富的工具和功能,方便用户进行文档编辑和管理;
6. 具有高级安全性设置和数字签名功能,确保文档的安全和认证。
by KpoJIuK, m0nkrus
– 集成了更新,因此原始版本 21.1.20135 变为版本 25.1.20474。
– 安装程序中添加了一个开始菜单,该菜单仿照 Creative Cloud 系列现代产品组件的类似菜单设计。
– 解锁在 Windows 7 SP1、Windows 8.x、Windows 10 小版本、Windows Server 2008R2-2012R2 上安装程序的能力。
– 删除了原始安装程序默认安装和启动的 Adobe 正版软件完整性服务。
– 禁用 Acrobat 自动更新服务,该服务由原始安装程序默认安装和启动。
– 禁用间谍模块日志传输应用程序、CRLog 传输应用程序和 Adobe 崩溃处理器。
– 该程序已经被处理。安装后即可立即使用。
编辑原因:05.04 更新 Adobe Acrobat Pro DC v2025.001.20474 m0nkrus 破解版
转载 Adobe Acrobat Pro DC v2025.001.20474 破解版 32位 & 64位-绿软小站
Adobe Acrobat Pro DC v2025.001.20474 破解版 32位 & 64位
种子下载 64位(已更新):https://url33.ctfile.com/f/2655733-1502876701-3cb98d?p=2023 (访问密码: 2023)
种子下载 32位(已更新):https://url33.ctfile.com/f/2655733-1502876698-1aa109?p=2023 (访问密码: 2023)
夸克云:https://pan.quark.cn/s/b353d05aef09
百度云:https://pan.baidu.com/s/18K7KNVHXiKSb-4HFEOgfSg?pwd=af1a
123 盘:https://www.123pan.com/s/N7M7Vv-HpQod.html
站长转存的不限速直链
http://ipv4.ncncy.com:5244/Adobe.Acrobat.Pro.2025.u5.x64.Multilingual.iso
如果你遇到Red Hat如下问题,可以尝试使用docker运行Aria2
无法读取客户身份 本系统尚未在权利服务器中注册。可使用 “rhc” 或 “subscription-manager” 进行注册。
# subscription-manager register 注册到:subscription.rhsm.redhat.com:443/subscription 用户名: xxxx 密码: xxx 无法注册到任何机构。
Alist 有官方的 Docker 镜像和部署文档。但我更倾向于使用 Docker Compose 来管理部署,这样可以将它和Aria2 Pro或其他应用一起部署。
docker-compose.yml文件,并参environment和volumes节点中照注释(#)进行配置。${PWD}指代当前目录,默认配置会将程序产生的数据保存在这个文件中,如果你想将数据保存在其他位置,可以修改volumes配置(:号前为主机上的目录,后为容器内的目录)。内容如下:
version: "3.8"
services:
# Aria2 Pro 的官方部署文档: https://github.com/P3TERX/Aria2-Pro-Docker/blob/master/docker-compose.yml
Aria2-Pro:
container_name: aria2-pro
image: p3terx/aria2-pro
environment:
- PUID=65534
- PGID=65534
- UMASK_SET=022
- RPC_SECRET=123456 # 配置Aria2 的 RPC secret 密钥,它将被用于 Alist 和 AriaNg 连接 Aria2,默认123456
- RPC_PORT=6800
- LISTEN_PORT=6888
- DISK_CACHE=64M
- IPV6_MODE=false
- UPDATE_TRACKERS=true
- CUSTOM_TRACKER_URL=
- TZ=Asia/Shanghai
volumes:
- ${PWD}/aria2/config:/config
- ${PWD}/aria2/downloads:/downloads # 在:号前配置你要在主机上保存下载文件的路径
ports:
- "6800:6800"
- "6888:6888"
- "6888:6888/udp"
restart: unless-stopped
logging:
driver: json-file
options:
max-size: 1m
# Aria2 的 Web UI
AriaNg:
container_name: ariang
image: p3terx/ariang
command: --port 6880 --ipv6
ports:
- "6880:6880"
restart: unless-stopped
logging:
driver: json-file
options:
max-size: 1m
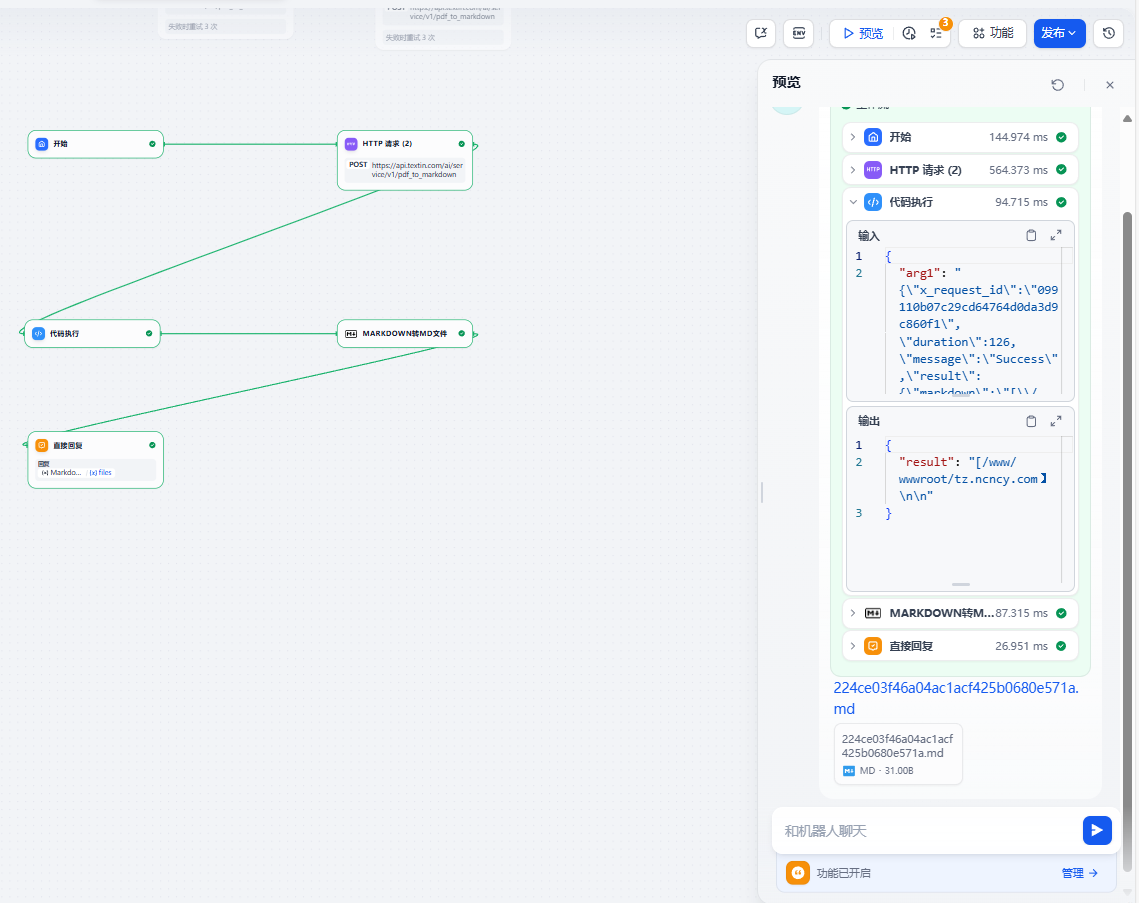
docker-compose up -d命令,就能完成部署了。将http节点返回的内容如
{
"status_code": 200,
"body": "{\"x_request_id\":\"5d54bffb67988fff2f59e055a3b54ea1\",\"duration\":137,\"message\":\"Success\",\"result\":{\"markdown\":\"[\\/www\\/wwwroot\\/tz.ncncy.com】\\n\\n\",\"success_count\":1,\"pages\":[{\"angle\":0,\"page_id\":1,\"content\":[{\"pos\":[3,8,223,8,223,29,3,29],\"id\":0,\"score\":0.98100000619888,\"type\":\"line\",\"text\":\"[\\/www\\/wwwroot\\/tz.ncncy.com】\"}],\"status\":\"Success\",\"height\":35,\"structured\":[{\"pos\":[3,11,223,11,223,25,3,25],\"type\":\"textblock\",\"id\":0,\"content\":[0],\"text\":\"[\\/www\\/wwwroot\\/tz.ncncy.com】\",\"outline_level\":-1,\"sub_type\":\"text\"}],\"durations\":117.35350799561,\"image_id\":\"\",\"width\":225}],\"valid_page_number\":1,\"total_page_number\":1,\"total_count\":1,\"detail\":[{\"paragraph_id\":0,\"page_id\":1,\"tags\":[],\"outline_level\":-1,\"text\":\"[\\/www\\/wwwroot\\/tz.ncncy.com】\",\"type\":\"paragraph\",\"position\":[3,11,223,11,223,25,3,25],\"content\":0,\"sub_type\":\"text\"}]},\"metrics\":[{\"angle\":0,\"page_id\":1,\"status\":\"Success\",\"duration\":135.72903442383,\"page_image_width\":225,\"page_image_height\":35}],\"code\":200,\"version\":\"3.15.13\"}",
"headers": {
"date": "Mon, 28 Apr 2025 03:11:58 GMT",
"content-type": "application/json;charset=utf-8",
"content-length": "1002",
"connection": "keep-alive",
"access-control-max-age": "86400",
"access-control-allow-origin": "*",
"access-control-allow-headers": "Content-Type,token,No-Cache,Pragma,Cache-Control,X-Requested-With,x-ti-app-id,x-ti-secret-code",
"access-control-expose-headers": "X-Request-Id",
"server": "Intsig Web Server",
"strict-transport-security": "max-age=3600; includeSubDomains; preload",
"x-request-id": "5d54bffb67988fff2f59e055a3b54ea1"
},
"files": []
}得到的是一个”body”中含\”markdown\”的格式,我们使用代码节点提取markdown内容
import json
def main(arg1: str) -> dict:
# 将arg1(JSON字符串)解析为字典
data = json.loads(arg1)
# 提取result部分的markdown字段
markdown_content = data.get("result", {}).get("markdown", "")
# 返回提取的markdown内容
return {
"result": markdown_content,
}再使用markdown转文件节点得到你需要的内容格式
“她有优点吗?”
“像太阳一样少”
“她有缺点吗?”
“像繁星一样多”
“那你为什么还爱她”
“因为太阳一出来星星就不见了”
import re
def main(text: str) -> dict:
pattern = r'\|.*\|\n\|.*\|\n(\|.*\|\n)*'
matches = re.findall(pattern, text)
if matches:
table = matches[0].strip()
rows = [row.strip() for row in table.split('\n')]
headers = [h.strip() for h in rows[0].split('|')[1:-1]]
data = []
for row in rows[2:]:
cells = [c.strip() for c in row.split('|')[1:-1]]
data.append(dict(zip(headers, cells)))
return {'result': data}
return {'result': []}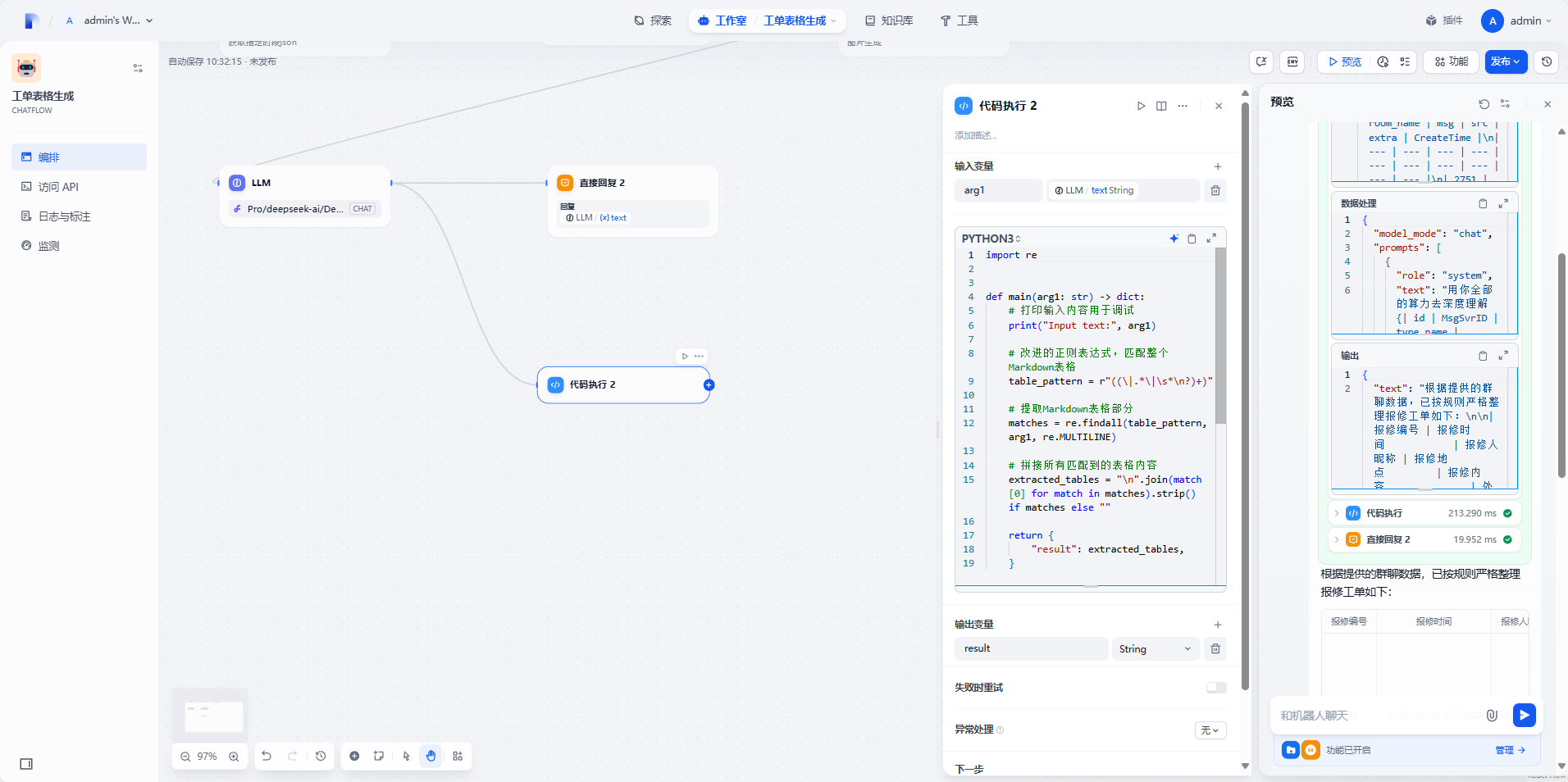
(如 ‘\u672a\u53d1\u73b0\u6f0f\u6c34\u6765\u6e90’)的输入参数转换成实际的中文字符:(’未发现漏水来源’)
import json
def main(arg1: str) -> dict:
# 将Unicode编码转换为中文字符
decoded_arg1 = bytes(arg1, 'utf-8').decode('unicode_escape')
return {
"result": decoded_arg1,
}import os
import time
import win32file
import win32con
import pywintypes
def detect_key(dat_content):
"""
通过分析文件内容自动检测密钥
"""
# 常见的图片文件头
common_headers = {
b'\xFF\xD8': 'jpg', # JPEG 文件头
b'\x89\x50': 'png', # PNG 文件头
b'\x47\x49': 'gif', # GIF 文件头
b'\x42\x4D': 'bmp', # BMP 文件头
}
for key in range(256): # 尝试所有可能的密钥 (0-255)
decrypted_data = bytes([byte ^ key for byte in dat_content[:2]]) # 只解密前两个字节
for header, format_name in common_headers.items():
if decrypted_data.startswith(header):
return key, format_name
return None, None
def set_file_creation_time(file_path, creation_time):
"""
使用 pywin32 设置文件的创建时间
"""
# 将时间戳转换为 pywintypes 时间对象
win_time = pywintypes.Time(creation_time)
# 打开文件句柄
handle = win32file.CreateFile(
file_path,
win32con.GENERIC_WRITE,
0,
None,
win32con.OPEN_EXISTING,
0,
None
)
# 设置文件的创建时间
win32file.SetFileTime(handle, win_time, None, None)
win32file.CloseHandle(handle)
def decode_wechat_image(dat_file, output_folder):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取原文件的创建时间
creation_time = os.path.getctime(dat_file)
with open(dat_file, 'rb') as f:
dat_content = f.read()
# 获取文件名的前缀
file_name = os.path.basename(dat_file).split('.')[0]
# 自动检测密钥
key, image_format = detect_key(dat_content)
if key is None:
print(f"无法检测到密钥或识别图片格式: {dat_file}")
return
# 解密并保存图片
decrypted_data = bytes([byte ^ key for byte in dat_content])
output_file = os.path.join(output_folder, f"{file_name}.{image_format}")
with open(output_file, 'wb') as f:
f.write(decrypted_data)
# 设置新文件的创建时间为原文件的创建时间
set_file_creation_time(output_file, creation_time)
print(f"图片已保存到: {output_file} (创建时间已保留)")
def batch_decode_wechat_images(input_folder, output_folder):
for root, dirs, files in os.walk(input_folder):
for file in files:
if file.endswith('.dat'):
dat_file = os.path.join(root, file)
decode_wechat_image(dat_file, output_folder)
if __name__ == "__main__":
input_folder = r'C:\Users\yangy\Documents\WeChat Files\wxid_4ipvtcu7uzyk12\FileStorage\MsgAttach\454fe72042640d5aaed6d8b2aa470459\Thumb\2025-03'
output_folder = r'E:\微信捕捉\weixin捕捉\jiemi\图片2'
batch_decode_wechat_images(input_folder, output_folder)更改input和output地址为自己电脑的地址